Challenges and Solutions in Building a Large-Scale Cluster with Kubernetes and Istio
As discussed in this blog post, the Houzz Infrastructure Engineering Team recently completed a major web server farm migration from the Amazon Elastic Compute Cloud (Amazon EC2) to a new Kubernetes cluster in order to better manage the growing number of services and growth in traffic volume to Houzz. The migration led to up to 30% improvement in our top page latencies and roughly 33% reduction in compute resources.
The overall architecture of the new Kubernetes cluster incorporates multiple applications, including a frontend (FE) application written in NodeJS and a backend (BE) service written in HHVM. The FE application communicates with the BE service through the Apache Thrift protocol over HTTP. Horizontal Pod Autoscaling (HPA) is enabled for each application. Networking within the cluster and with external services are managed by Istio. All networking in each pod goes through the Envoy sidecar running in the pod.
The migration was not without its challenges, a few of which we will share here in an effort to help other teams learn from the solutions we developed to achieve a successful outcome.
Pod Startup Delay
As we began our Kubernetes migration, we noticed pod startup delays that happened occasionally on newly provisioned nodes. It took about six minutes for the Envoy container to become ready, blocking the initiation of other containers. From the Envoy log, we observed pilot-agent continuously reporting that Envoy was not ready with a suggestion to check if Istiod was still running.
We implemented a daemonset whose only job was to resolve FQDN of the Istiod service. From its metric, we observed that the Domain Name System (DNS) name resolution timed out for a few minutes after the bootstrap of a new node and believed that Envoy suffered from the same timeout problem.
We identified the option dnsRefreshRate, whose default value in Istio 1.5.2 is 5 minutes and roughly matched the observed delay. Since the DNS client on a new node becomes ready after some pods have started, the long retry interval caused Envoy to fail to detect the readiness of the DNS client in time. By forcing Envoy to retry more frequently, we decreased the additional pod startup delay from 360 seconds to 60 seconds.
Note that the default dnsRefreshRate was changed to 5 seconds in Istio 1.6.
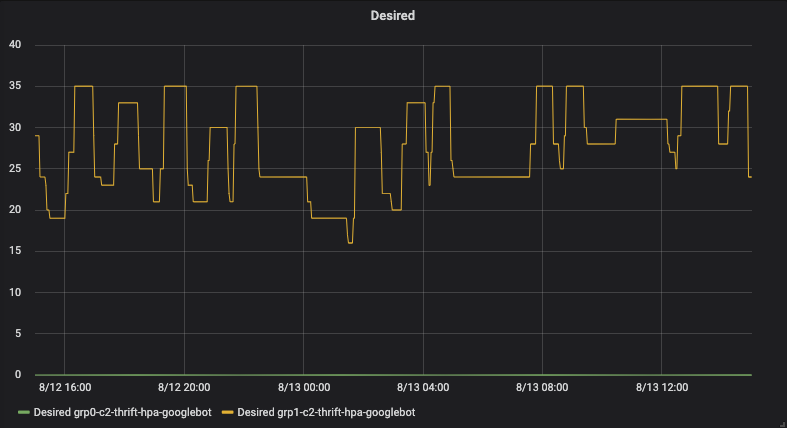
HHVM Pod Warmup And Cascading Scaling
Our BE services are built in HHVM, which is known to have high CPU usage and high latency until its code cache has warmed up. The warmup phase typically takes several minutes so it did not work well with the default 15 second HPA sync period, or the interval at which HPA evaluates the CPU usage metrics and adjusts the number of desired pods. When new pods were created due to the increased load, HPA detected higher CPU usage from the new pods and scaled up even more pods. This positive feedback loop continued until the new pods were fully warmed up, or until the maximum number of pods were reached. After the new pods were fully warmed up, HPA detected a significant drop in CPU usage and scaled down a large number of pods. The cascading scaling resulted in instability and latency spikes.
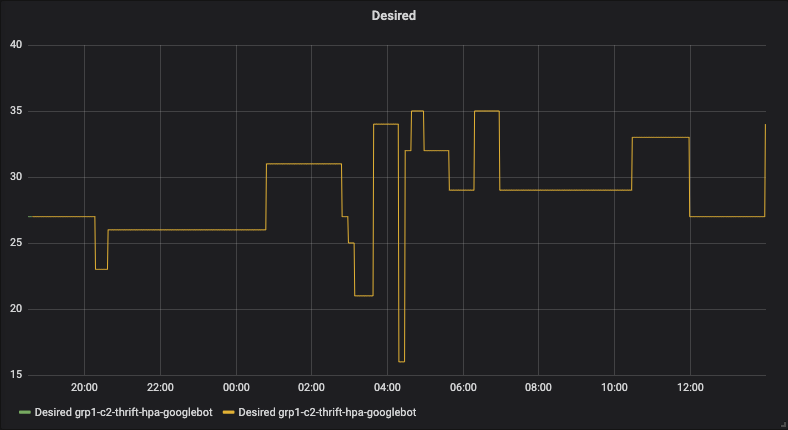
We made two changes to address the cascading scaling issue. We improved the HHVM warmup process based on their official recommendation. The CPU usage during the warmup was reduced from 11 to 1.5 times that of normal usage. The CPU usage after the pod started to serve traffic was reduced from 4 to 1.5 times that of normal usage.
In addition, we increased the HPA sync period from 15 seconds to 10 minutes. While HPA would respond slower to load increases, it avoided the cascading scaling because most pods could finish warming up and start normal CPU usage within 10 minutes. We found this to be a worthwhile trade off.
HPA activity before the changes:
HPA activity after the changes:
Load Imbalance
Load imbalance was the most noteworthy challenge we encountered during the migration to Kubernetes, though it only happened in the largest Virtual Service. The symptom was that some pods would fail the readiness checks under heavy load, then significantly more requests would be routed to those pods, causing the pods to flap between ready and unready states. Adding more nodes or pods in that situation would lead to even more flapping pods. When it happened, the latency and error count increased significantly. The only way to mitigate the issue was to forcefully scale down the deployment to kill the flapping pods without adding new ones. However, it was not a sustainable solution since more pods would soon begin to flap under the heavier load. We reverted the migration multiple times due to this issue.
Load imbalance:
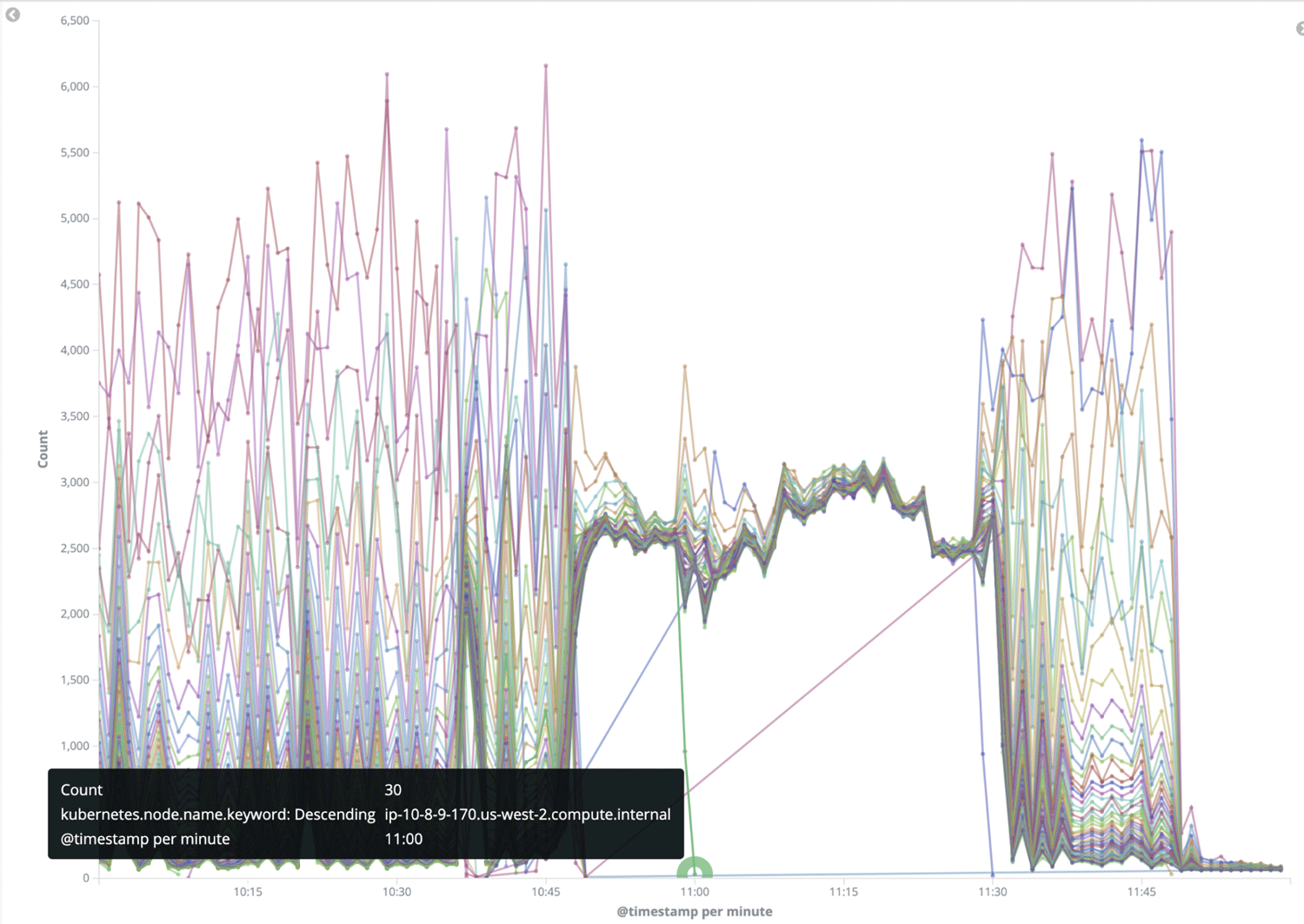
To help with the investigation, we added additional logging and found that when the load imbalance was triggered, one availability zone (AZ) had significantly more requests than the other two. We suspected that the imbalance was due to a positive feedback loop in the Least Request load balancing policy we used at that time. We tried several other policies (Round Robin, Locality Aware and Random), but none of them fixed the imbalance issue.
After we eliminated the load balancing policy as the suspect, we looked for the positive feedback loop in two other areas: retries on failed requests and outlier detection. Although it is stated in Istio’s official documentation that there is no retry for failed requests by default, the actual default number of retries is set to two. Retries are known to create cascading failures since more requests would be sent after some requests failed. In addition, we observed some behaviors in the outlier detection (otherwise known as passive health checks) which could not be explained, so we decided to disable both features. After that, the imbalance issue went away and we were able to migrate 95% of the requests to Kubernetes. We kept 5% on the old platform for performance comparison and tuning.
At first, we were unsure which of the two features, retries or outlier detection, was responsible for the load imbalance though we now believe it to be related to retries. After we upgraded Istio to version 1.6, made several performance improvements and migrated 100% of the requests to Kubernetes, we tried re-enabling the outlier detection — a risk we were willing to take because the change could be reverted within a few seconds. At the time of writing, we have not re-encountered the load imbalance issue. That said, we caveat our theory with the fact that the current Istio version of the cluster configuration is not the same as the configuration when the imbalance happened.
Post-Release Performance Degradation
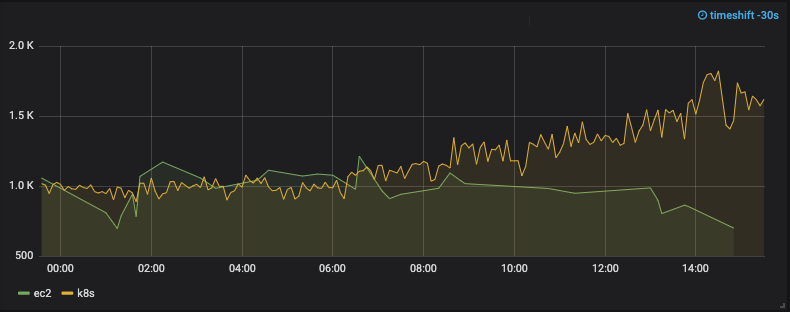
We observed that the latency on Kubernetes increased over time after each release, so we created a dashboard to show the inbound/outbound latencies reported by Envoy in the ingress gateway, FE application and BE service pods. The dashboard indicated that the overall increase was driven by the rise in the inbound latency reported by Envoy in the BE pods, which includes the service latency and the latency in Envoy itself. Since there was no significant increase in the service latency, the proxy latency was believed to be the driver to the latency increase.
We found that Envoy’s memory usage in the BE pods was also increasing over time after each release, which led us to suspect that the latency increase was caused by a memory leak from Envoy in the BE pods. We executed into a BE pod and listed the connections in Envoy and the main container and found that there were about 2,800 connections in Envoy and 40 in the main container. The vast majority of the 2,800 connections were with the FE pods (the clients of the BE pods).
We tested several changes in order to address the Envoy memory leak issue, including:
1. Reducing the idleTimeout for the connections between FE pods to BE pods from the default one hour to 30 seconds. The change reduced the number of errors and increased the request success rate, but also increased the number of connection requests per second between the FE and BE pods.
2. Decreasing the concurrency, or the number of threads, in Envoy from 16 to two in the FE pods. The change cancelled most of the increases in the number of connection requests per second from the first change.
3. Setting the Envoy memory limit to 300MB in the BE pods. The expected behavior was observed and Envoy restarted when its memory usage exceeded the limit. The pod continued to run, but with lower memory usage. Some pods had a short period of unreadiness when Envoy was restarted, which was complementary to the first two changes. While the first two changes reduced Envoy’s memory usage, the third would restart Envoy when its memory usage exceeded the limit. Restarting Envoy caused significantly less down time than restarting the main container, because the latter would incur several minutes of warmup time in HHVM.
Latency before the changes:
Memory usage before the changes:
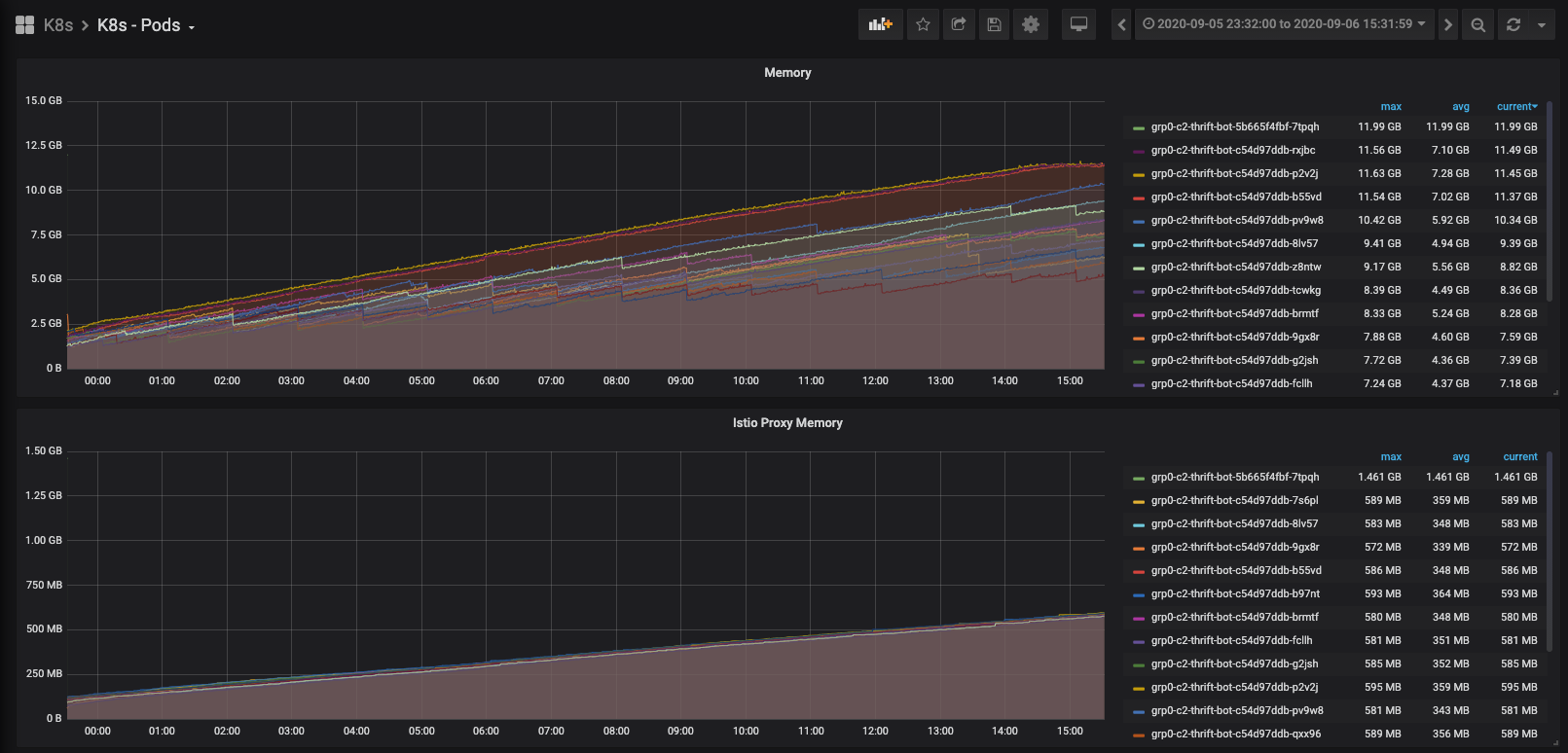
Latency after the changes:
After the post-release performance degradation issue was addressed, we migrated 100% of requests to Kubernetes and shut down the old hosts.
Cluster-Wide Bottlenecks
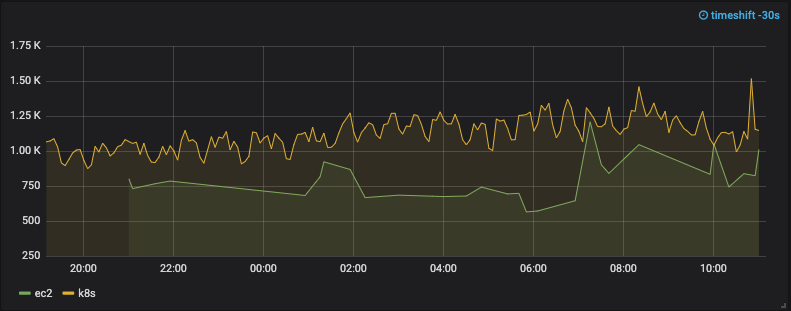
As we migrated more requests to the largest Virtual Service in Kubernetes, we encountered issues with cluster-wide resources that were shared across Virtual Services, including the API server, the DNS server and the Istio control plane.
Error spikes were observed across all Virtual Services which lasted one or two minutes during an incident and we found that it was due to a failure to resolve the DNS name for the BE Virtual Service in the FE pods. The error spikes were also correlated with the DNS resolution errors and drops in DNS requests.
The in-mesh service calls were not expected to depend on DNS. Instead, Envoy in the FE pod was supposed to direct the outgoing HTTP request to the IP address of an endpoint in the BE service. However, we discovered that the NodeJS Thrift client library did a DNS lookup for a useless service IP. To remove the DNS dependency, we deployed a sidecar to bind the host for BE service in Virtual Service to a local socket address.
Sidecar manifest example:
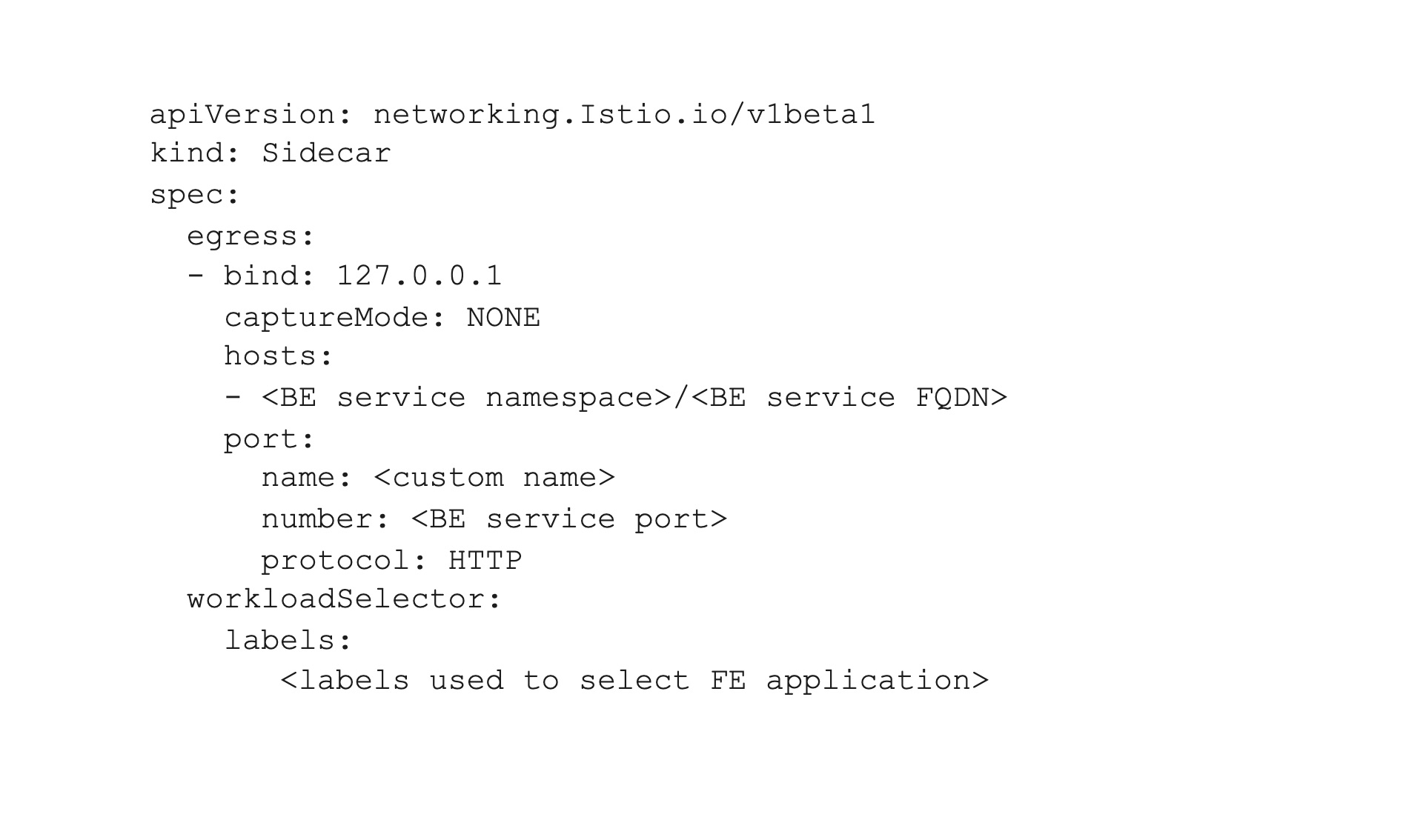
Though Istio maximizes transparency from the application perspective, we had to explicitly add the Host header, in addition to replacing the DNS name with local IP address and port number in our application code.
It’s worth mentioning that a side benefit of sidecar is the memory usage optimization. By default, Istio adds an upstream cluster for each service across the Kubernetes cluster into Envoy, regardless of whether it’s needed. One significant cost for maintaining those unnecessary configurations is memory usage of the Envoy container.
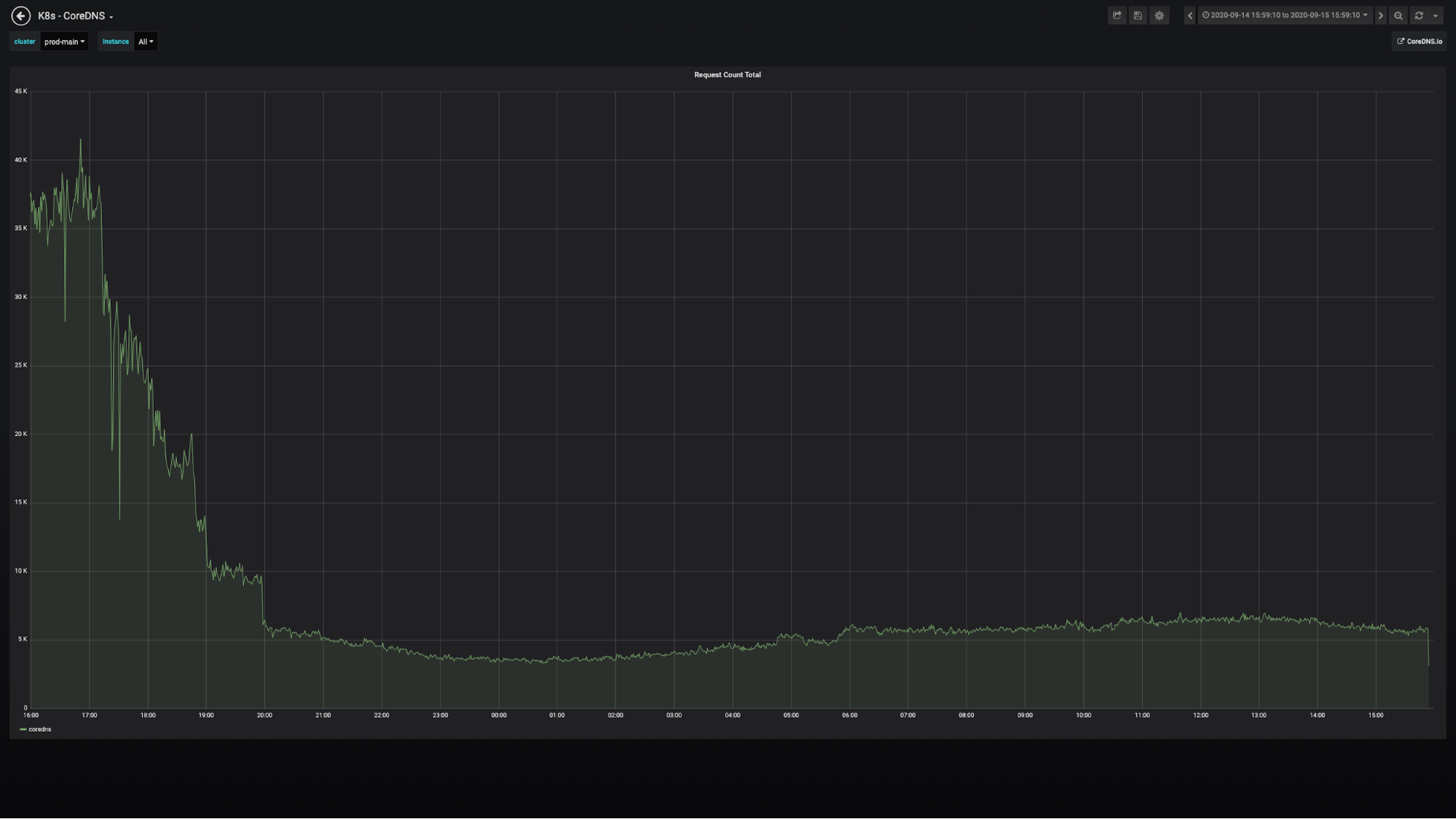
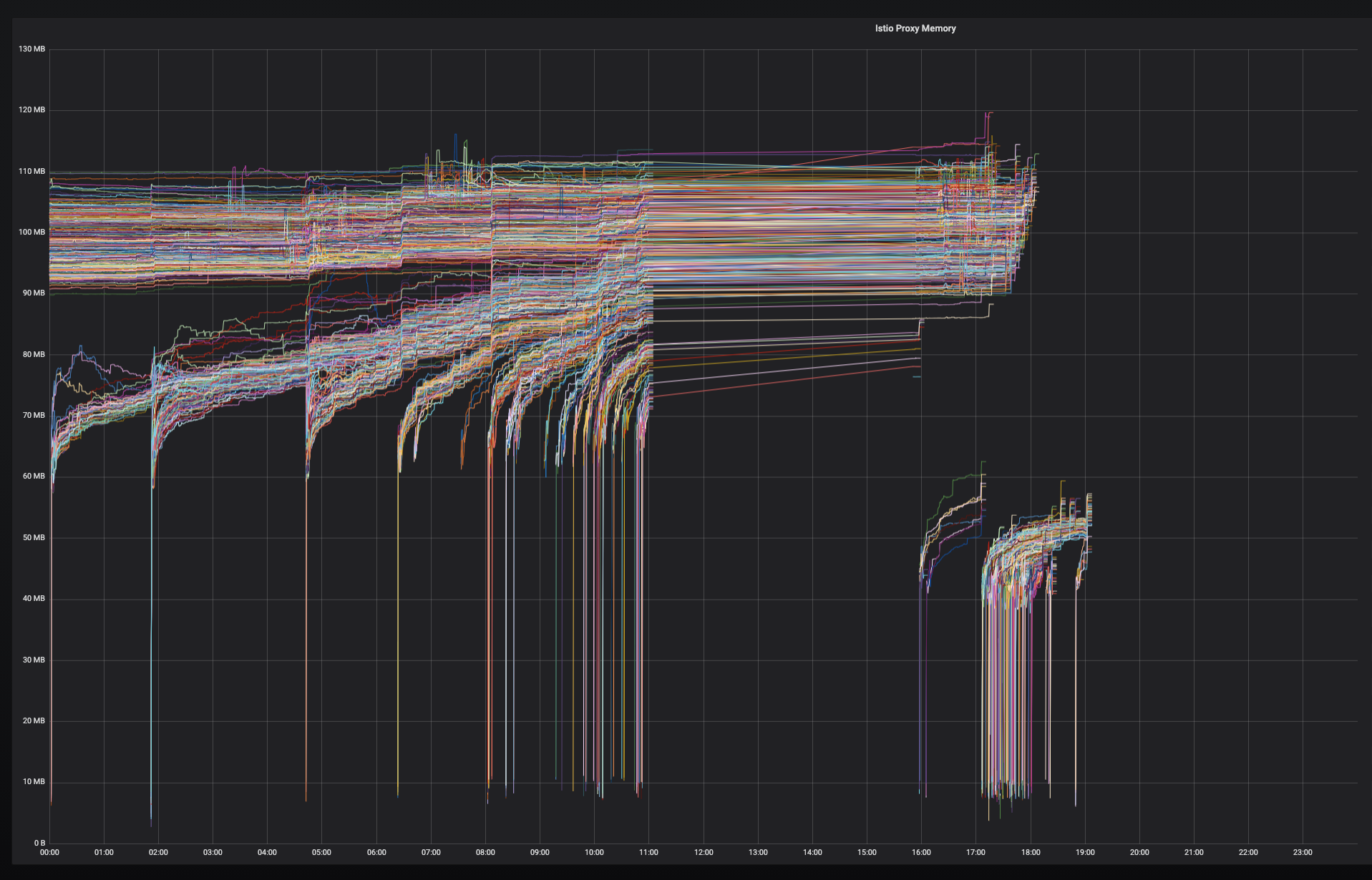
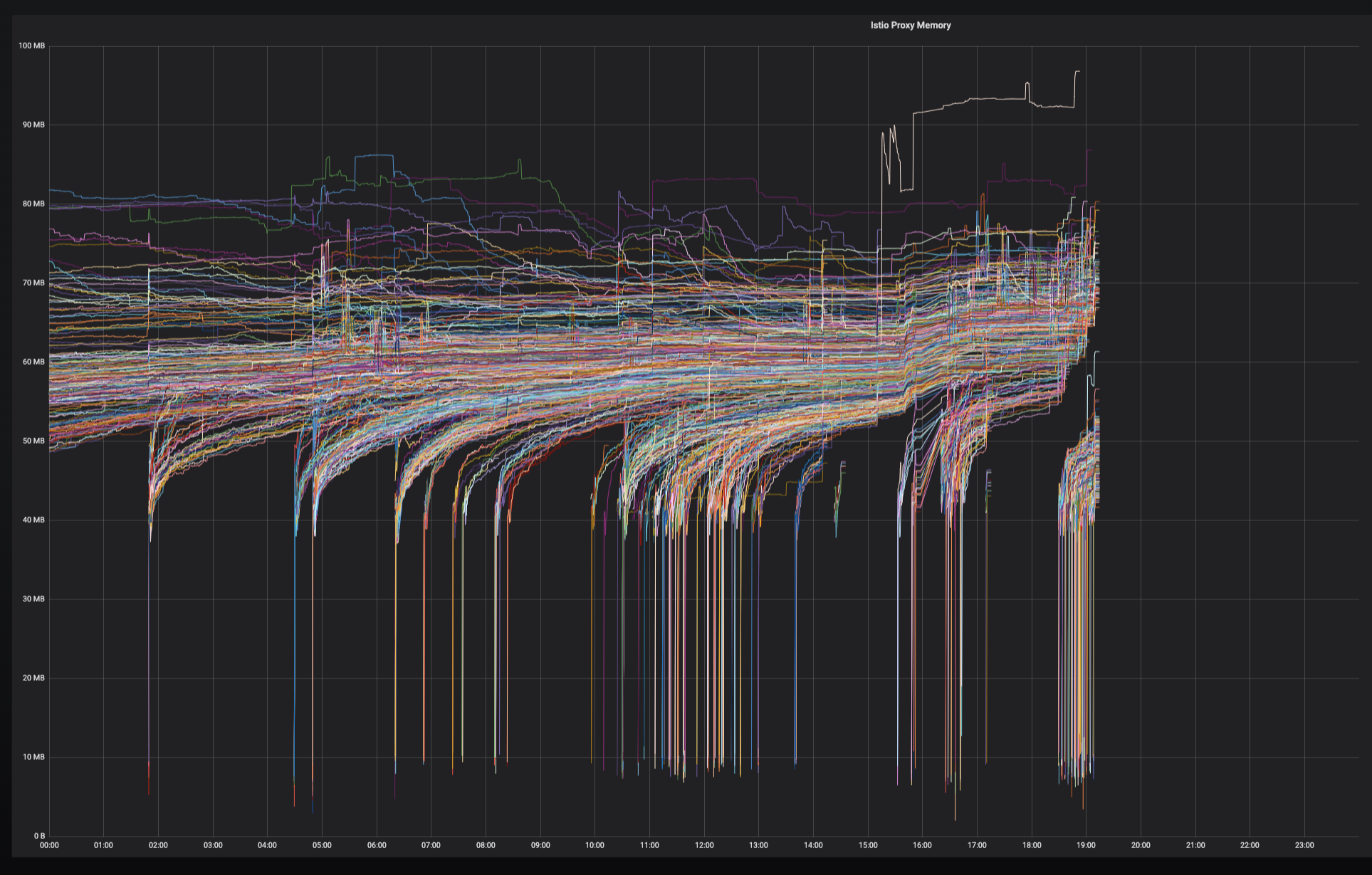
With the sidecar solution, we isolated DNS server failure from service call in critical path, reduced QPS on DNS server from 30,000 to 6,000, as well as decreased the average memory usage of Envoy from 100MB to 70MB.
QPS change on coreDNS:
Memory usage before the changes:
Memory usage after the changes:
Another error spike we encountered was correlated with inconsistent cluster memberships and node terminations. Although Kubernetes was supposed to handle node terminations gracefully, there was a special case in the node termination that led to the error spike: an Istiod pod was running on the terminating node. After the node was terminated, it took about 17 minutes for some FE pods to receive an update from a new Istiod pod. Before they received the update, they had inconsistent views of the BE cluster membership. Given that, it’s highly likely that cluster membership in those problematic FE pods were out-of-date, leading them to send requests to terminated or unready BE pods.
Inconsistent and stale cluster membership:
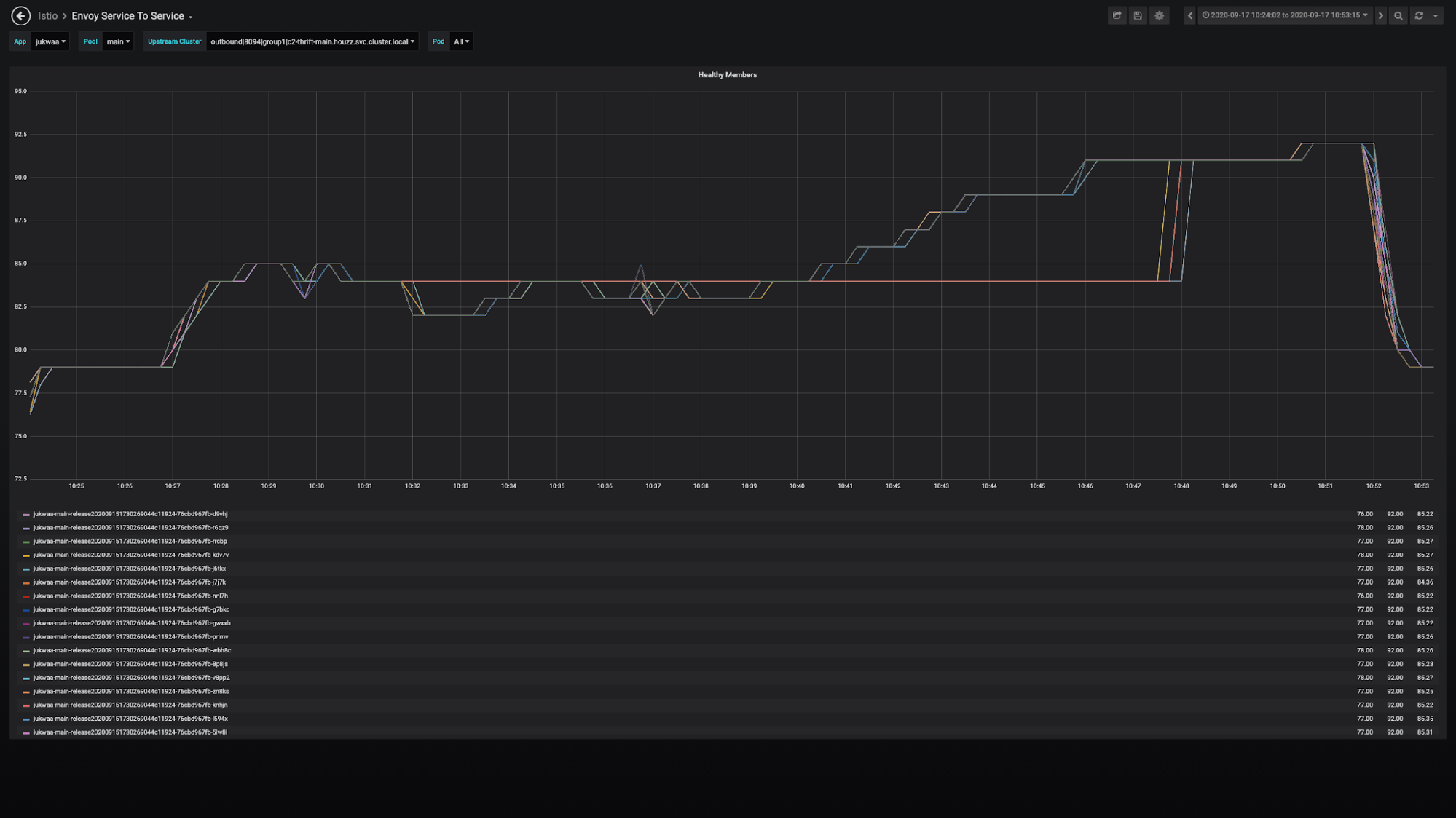
We found that the tcpKeepalive options played a role in detecting terminated Istiod pods. In our Istio setup, keepaliveTime, keepaliveProbes and keepaliveInterval were set to the default values 300 seconds, 9 and 75 seconds, respectively. Theoretically, it could take at least 300 seconds plus 9, multiplied by 75 seconds (16.25 minutes) for Envoy to detect a terminated Istiod pod. We fixed it by customizing tcpKeepalive options to much lower values with no false-positives.
Building a large scale Kubernetes cluster was a challenging and rewarding experience. We hope you have found useful information from our experiences. If you are interested in joining our team, please check out our openings at houzz.com/jobs.


