Migration to Redis Cluster
At Houzz, we use Redis as the de-facto in-memory data store for our applications, including the web servers, mobile API servers and batch jobs. In order to support the growing demands of our applications, we migrated from an ad hoc collection of single Redis servers to Redis Cluster during the first half of the year.
To date, we have gained the following benefits from the migration:
– Ability to scale up without the need to modify applications.
– No additional proxies between clients and servers.
– Lower capacity requirement and lower operational cost.
– Built-in master/slave replication.
– Greater resilience to single point of failures.
– Functional parity to single Redis servers, including support for multi-key queries under certain circumstances.
Redis Cluster also has limitations. It does not support environments where IP addresses or TCP ports are remapped. Although it has built-in replication, as we ultimately discovered, few client libraries, if any, have support for it. For certain operations such as new connection creation and multi-key operations, Redis Cluster has longer latencies than single servers.
In this post, we will share our experiences with the migration, the lessons we learned, the hurdles we encountered, and the solutions we proposed.
Functional Sharding
Some of our applications use Redis as a permanent data store, while others use it as a cache. In a typical setting, there is a Redis master that processes write requests and propagates the changes to a number of slaves. The slaves serve only read requests. One of the slaves is configured to dump the memory to disk periodically. The dumps are backed up into the cloud. We use Redis Sentinel to do automatic failover from failed masters to slaves. Our applications access Redis through HAProxy.
Historically we scaled up the Redis servers by “functional” sharding. We started with a single shard. When we were about to run out of capacity, we added another shard and moved a subset of the keys from the existing shard to the new one. The new shard is typically dedicated to keys for a specific application or feature, e.g., ads or user data. Code that accessed the moved keys was modified to access the new servers after the move. For example, the marketplace application would access shards that store data about the products and merchants in the marketplace, while the consumer-oriented applications would access shards that store user data such as activities and followed topics. The same process was repeated for several years and the number of servers grew to several dozens. The process remained mostly manual due to the need to modify the applications.
The Redis servers ran on high-end hosts that had a large memory capacity. Such hosts would typically also have a large number of processors. Since each Redis server is a single process, only a small fraction of processors are utilized on each host. In addition, there is imbalance in memory and CPU usages across the shards due to the manual partitioning. Some shards have a large memory footprint and/or serve a high requests per second.
The large memory footprints are problematic to operations such as restart and master-slave synchronization. It can take more than 30 minutes for a large shard to restart or to do a full master-slave sync. Since all our client requests depend on Redis accesses, it poses a risk for a severe site-wide outage should all replicas of the large shard go down.
In the beginning of the year, we evaluated options to scale up the Redis servers with fewer manual processes and a shorter time to production.
Redis Cluster vs. Twemproxy
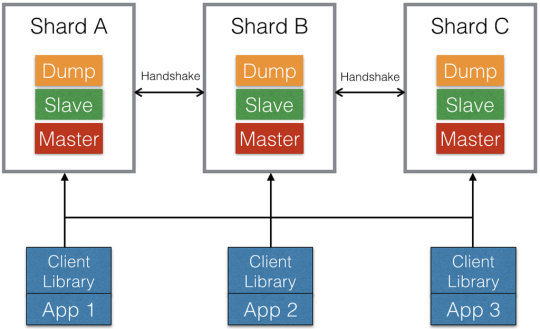
One option we considered was Redis Cluster. It was released by the Redis community on April 1, 2015. It automatically shards data across multiple servers based on hashes of keys. The server selection for each query is done in the client libraries. If the contacted server does not have the queried shard, the client will be redirected to the right server.
There are several advantages with Redis Cluster. It is well documented and well integrated with Redis core. It does not require an additional server between clients and Redis servers, hence has a lower capacity requirement and a lower operational cost. It does not have a single point of failure. It has the ability to continue read/write operations when a subset of the servers are down. It supports multi-key queries as long as all the keys are served by the same server. Multiple keys can be forced to the same shard with “hash tags”, i.e., sub-key hashing. It has built-in master-slave replication.
As mentioned above, Redis Cluster does not support NAT’ed environments and in general environments where IP addresses or TCP ports are remapped. This limitation makes it incompatible with our existing settings, in which we use Redis Sentinel to do automatic failover, and the clients access Redis through HAProxy. HAProxy provides two functions in this case: It does health checks on the Redis servers so that the client will not access unresponsive or otherwise faulty servers. It also detects the failover that is triggered by Redis Sentinel, so that write requests will be routed to the latest masters. Although Redis Cluster has built-in replication, as we discovered later, few client libraries, if any, have support for it. The open source client libraries we use, e.g., Predis and Jedis, would ignore the slaves in the cluster and send all requests to the masters.
The other option we evaluated was Twemproxy. Twitter developed and launched Twemproxy before Redis Cluster was available. Like Redis Cluster, Twemproxy automatically shards data across multiple servers based on hashes of keys. The clients send queries to the proxy as if it is a single Redis server that owns all the data. The proxy then relays the query to the Redis server that has the shard, and relays the response back to the client.
Like Redis Cluster, there is no single point of failure in Twemproxy if multiple proxies are running for redundancy. Twemproxy also has an option to enable/disable server ejection, which can mask individual server failures when Redis is used as a cache vs. a data store.
One disadvantage of Twemproxy is that it adds an extra hop between clients and Redis servers, which may add up to 20% latency according to prior studies. It also has extra capacity requirement and operational cost for monitoring the proxies. It does not support multi-key queries. It may not be well integrated with Redis Sentinel.
Based on the above comparison, we decided to use Redis Cluster as the scale-up method going forward.
Building the cluster
Before we could migrate to Redis Cluster, we needed to bring Redis Cluster to functional parity to functional shards. We implemented most of the improvements in our client libraries (e.g., the Predis library for PHP clients). We also built automation tools for cluster management in our infrastructure management toolkit salt.
As mentioned earlier, the main missing features in the client libraries for Redis Cluster are master-slave replication, health checks and master-slave failover.
We replaced the active health checks in HAProxy with passive mark down and retries in the PHP client library. When the client gets an error from a Redis server, e.g., connection timeout or unavailability due to loading, the client marks the server down in APC and retries another server. Since APC is shared by all PHP processes in the same web server, the marked down Redis server will not be accessed by another client until it expires from APC a few seconds later.
We also added support for cluster master-slave replication in the client library. It started out as a straightforward refactoring, but ended up with considerable complexity as it interacted with the passive health checks and retries in partial failure modes, especially in pipeline execution. I will discuss this in more detail later in the post.
Other improvements we made to the Predis library include:
– Support multi-server commands such as mset and mget
– Reduction of memory usage of cluster configuration such as slot-to-server maps
– Bug fixes including memory leak fixes, etc.
– Added pipeline support to the Java Redis library Jedis.
Figures 1 and 2 show the Redis system architectures before and after the migration to Redis Cluster, respectively.
Figure 1. Functional shards
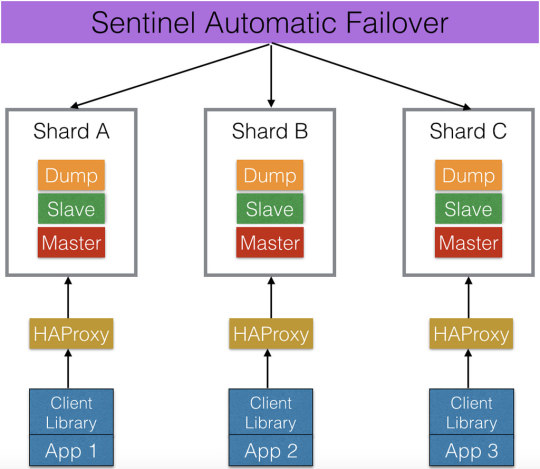
Figure 2. Redis Cluster
In addition to the client library improvements, we built tools to further automate the creation and maintenance of Redis Cluster.
There is an existing tool (redis-trib.rb) to create a cluster from a set of Redis servers. We built tools to place the masters and slaves in a more deterministic way than what redis-trib.rb does.
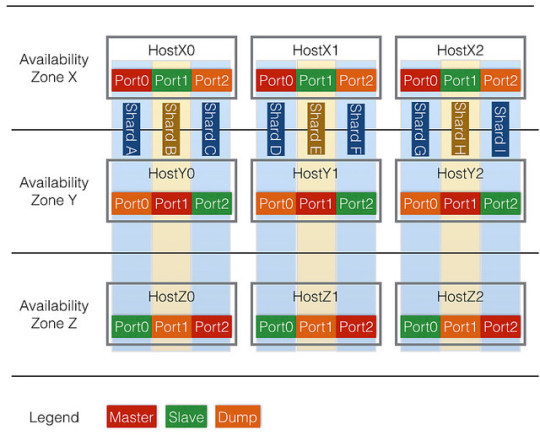
For example, we place the servers of the same shard across availability zones for better fault tolerance.
For data persistence, we enable one server per shard to dump its memory to disk and upload the dumps to the cloud storage periodically. Memory dump is a resource intensive operation, therefore, we chose a slave vs. the master for dumping and distributed the masters and dumping slaves evenly across hosts for load balancing.
Another desirable feature of the layout is to have servers in the same shard to have the same port number, which eases manual operations during debugging.
We built a toolkit to implement the desired layout during cluster creation as well as subsequent additions of new cluster nodes. Figure 3 shows an example layout of our Redis Cluster.
Since automatic failover can happen in the cluster from time to time, our toolkit periodically collects the cluster status and reconfigures the servers when necessary.
Figure 3. Example layout of Redis Cluster
Before the migration, we ran a set of performance tests to compare the latency of Redis Cluster vs. functional shard under various conditions.
Figure 4 shows the latencies with non-persistent connections on cluster vs. functional shard. While there is a significant difference for the multi-key commands, we do not expect such cases to be common in practice for Redis Cluster since all Redis accesses in the same client session will be able to share the same connection to the cluster.
Figure 4. Latencies with non-persistent connections
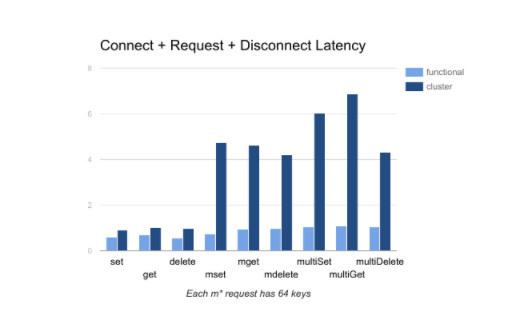
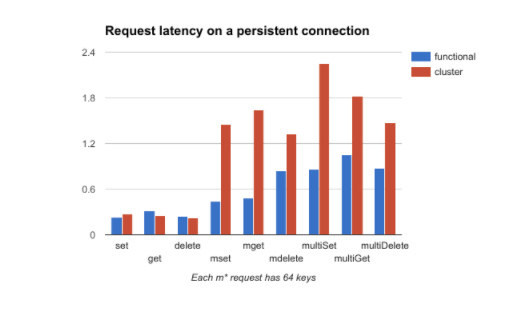
Figure 5 shows the latencies with persistent connections on cluster vs. functional shard. The latencies are measured when there is only one client accessing Redis. In practice, there will be multiple clients and the actual latency per request will the increased by the processing time of the requests that are queued in front of this request. The queues will be shorter in Redis Cluster since the workload is distributed across a larger number of processes.
Figure 5. Latencies with persistent connections
The live migration
According to the Redis Cluster documentation, no automatic live migration to Redis Cluster is currently possible and we have to stop the clients during the migration. Stopping the clients is not an option for us because it means shutting down the whole site.
We built our own live migration tool based on the append-only-file (AOF) feature in Redis. The AOF, when initially created, consists of a sequence of commands that can be replayed on a second server to reconstruct the data set in the first server that creates the file. Commands that the first server receives after the AOF is created will be appended to the file, hence the name “append only file”. Redis can be configured to rewrite the file when it gets too big. After the rewrite, the commands at the end of the old file may be re-ordered.
Our automatic live migration process involves the following steps:
1. Pick a slave in the functional shard that has dumping disabled.
2. Enable AOF in the picked slave but disable AOF rewrite, so that subsequent commands will not be re-ordered in the file.
3. Write a certain key, e.g., “redis:migration:timestamp”, to the functional shard to serve as a bookmark for later use.
4. Copy the AOF from the functional shard slave to all the hosts in the cluster.
5. Replay the AOF on each master in the cluster, using the “redis-cli –pipe” command.
6. Extract the new commands in the functional shard AOF that were added after the last bookmark, and store them in a delta file.
7. Repeat steps 3 – 5 with the new delta file instead of the full AOF.
8. When the number of new commands in the delta file drops below a certain threshold, we make a live configuration change to the clients so that they will start to access the cluster instead of the functional shard.
9. We continue to repeat steps 3 – 7 after the configuration change, until the number of new commands in the delta file drops to a lower threshold.
The live migration of each functional shard took from a few minutes to a few hours, depending on the size of the shard. The process went smoothly modular a few errors from the functional shard slave due to overloading from the AOF writes.
Post migration outage
After we migrated about ¾ of the functional shards to the cluster, something unexpected happened. We created the cluster with the same capacity as the functional shards. However, the size of our data grew faster than we expected.
The Redis cluster was overcommitted in memory and started to swap in early May. An issue with a backup script resulted in high volumes of disk reads and writes, and triggered the first failover when a Redis master on the same host tried to access the swap space. The failover then triggered a sequence of cascading events.
Slaves were unresponsive during failover, triggering cross-shard slave migrations, i.e., healthy slaves changed their masters. The failovers and cross-shard migrations resulted in an imbalanced distribution of masters and dumping slaves across hosts. The hosts with more dumping slaves were overloaded when the slaves started to dump, and more failover/cross-shard migrations followed. Redis clients repeatedly retried when servers were unresponsive, and eventually held up all web server processes and caused site outages.
Recovery and resolution
It took three weeks to fully recover from the outage. During the process, we performed many operations such as resizing and resharding the cluster for the first time in production. We learned lots of lessons and made quite a few improvements to the error handling code in our client library.
The first step to recovery was to rebalance the cluster, i.e., to bring it back to the balanced layout as illustrated in Figure 3. Next, we added 50% more hosts to the cluster.
We ran into several issues while resharding the cluster, i.e., migrating data from existing servers to new servers. For a short period of time during the migration of a key, clients kept receiving “MOVED” responses from both the source and the destination servers of the migration, therefore kept retrying between the two servers until they eventually had stack overflow.
To contain the issue to the affected processes only, we applied a limit on the number of retries in this situation so that the affected processes would not generate too much load in the clients or servers. We also made the passive healthy checks in the client library more robust. The entire resharding process took 12 hours, during which a small percentage of requests failed while the site was functioning overall.
After the resharding, the old Redis servers reported a drop in their data size, but their memory usage did not drop, nor did their swap usage. Since they still had data stored in the swap space, they could have spikes in latencies and client timeouts. We learned that the unchanged memory usage was a result of fragmentation in jemalloc, the memory allocator used in Redis, and that the only way to defragmentation is to restart the servers.
The last step in our recovery process was to rolling-restart all the old servers. For each shard, we first restarted a slave, then force a failover to the restarted slave, causing the old master and the other slaves to resynchronize data from the new master. Resynchronization has the same effect as restart on memory usage. After the resynchronization was completed, all servers in the shard had their memory defragmented and their swap space freed.
The rolling restart was a rigorous stress test on the clients and servers, and prompted us to make more improvements in the error handling of the client library. One improvement is to have different timeout values for masters vs. slaves, and to never mark down a master in the passive health checks. Masters are more heavily loaded than slaves during failover and are a single point of failure for write operations. Therefore, we would rather try a bit more when a master is slow, than give up too soon.
Open Questions
Clustering is a relatively new technology in Redis. Through the experience of building, migrating, and resharding Redis Cluster, we learned about its limitations as well as its potential.
While the ability to automate scaling in Redis Cluster opens up many new opportunities, it also brings up new questions. Will we be able to scale infinitely? What’s the best way of supporting a mixture of permanent store use case and cache use case? How can we minimize the impact of resharding and rolling restart on production traffic? We look forward to experimenting and learning more about Redis Cluster.
If you’re interested in joining us, we’re hiring! Check out opportunities on our team at houzz.com/jobs.


